A year or so ago we’d upgraded our vCenter from 4.1 to 5.1, and with this upgrade, and some features built into our SAN, we got access VAAI. For example, removing a VM guest would tell the SAN that the guest had been removed, and if the data store had been thinly provisioned from the SAN, it’d clean up and shrink down the space used (in theory).
Another feature we discovered was something called “fast copy”. In layman’s understanding of this feature, when a storage vMotion request was created, the SAN was notified of the request, and the SAN would process the copying of the bits in the background. This is handy because it stops the data from being sent from SAN to host to SAN again. This causes a good speed up with regards to moving machines around.
There was a caveat to the “fast copy” feature that we stumbled across last year. Well, what we stumbled upon was an issue when using vMotion to move machines between SANs. What we didn’t clue in on was that this was because of VAAI and “fast copy”. When we first observed this issue, we didn’t realize the issue was between SANs, we just thought the issue was random. Our VM hosts had storage allocated from 2 different SANs at the time, and our naming convention was a little off, so identifying quickly that the data store was on a different SAN wasn’t entirely obvious at first.
Ultimately the issue presents itself as a vMotion timeout. When you start the vMotion, it zips along until it hits 32%. It then sits there for a few minutes, sometimes up to 5 or 10, then the guest becomes unresponsive. At this point VMware decides the migration has timed out, and rolls back. Sometimes it can take several minutes for the failed guest to start responding again. If the guest is shut down, it usually hangs around 36% for a few minutes, but eventually processes. The error usually looks like this:
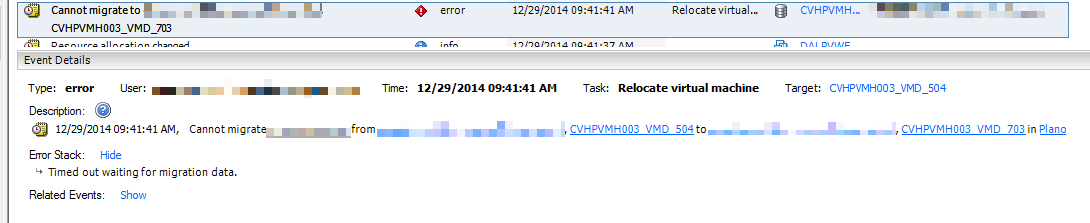
The error generally presented is “Timed out waiting for migration data.” It always happened at 32%. A bit of searching around, and I didn’t really uncover the cause of it. At the time we originally spotted this issue, we decided to take an outage and shut the guests down and vMotion them. This killed 2 stones at once, freed memory on the hosts, and gave the guests a reboot to clear memory and such.
Fast forward to nine months ago, and we had an issue where we discovered one of our SANs had become over saturated, and needed space and load removed from it. At this point, we now had a third SAN added to the mix, so we presented new data stores, and went through the process of trying to vMotion quite a lot of VM guests off of one set of data stores (actually 10) to another set. We hit the same wall as before, time outs at 32%. We put it down to the load and space issues on the SAN and went with the outage. This was our dev environment anyway, so it was less of an issue. We didn’t really look into it any further.
Jump forward to this past Tuesday. A sudden alert that multiple VMs had gone offline left us puzzled until we realized that one of the data stores had been way overprovisioned, and the backup software kicked off and with guest snapshots had filled the drive. With a quick bit of work, we moved some guests around, and bumped into the same 32% issue again. Shutting down some guests and shuffling them around got us through the pinch, but left me wondering.
After some experimentation, I was able to narrow down the cause of the issue on a single action. Storage vMotion between SANs. Inner SAN vMotion was snappy, 100GB in less than 2 minutes. Intra-SAN migrations would hit 32% and time out. That’s it, I had the cause of my problem. It had to be a fiber or switch issue… Right?
Not so much. While doing some digging on performance, our fiber switches, and SAN ports, I wasn’t spotting any obvious issues. Doing some searching again on our favourite web search engine, I stumbled across an HP document tucked away in the 3Par area (document was named mmr_kc-0107991, nice name). Bingo! Okay, the details don’t exactly match, for example the document mentions that it freezes at 10%, but it had all the hallmarks of what we were seeing. IntraSAN vMotion, timeouts, and VAAI.
So the solution was to disable VAAI on the host, do the vMotion, and then re-enable it if you still want to use it. VMware has a nice document on how to do that here in KB1033665. With a little PowerCLI1 we quickly disable VAAI and tested a vMotion on a live machine, and it worked. As we were working on a single cluster at the time, this is what we ended up with:
Get-VMHost -Location (Get-Cluster 'CVHPVMH003') | %{
Set-VMHostAdvancedConfiguration -VMHost $_ -Name DataMover.HardwareAcceleratedMove -Value 0
Set-VMHostAdvancedConfiguration -VMHost $_ -Name DataMover.HardwareAcceleratedInit -Value 0
Set-VMHostAdvancedConfiguration -VMHost $_ -Name VMFS3.HardwareAcceleratedLocking -Value 0
}
Once done, flip the 0s to 1s, and re-enable as needed.
-
This is something they actually give you in the KB article as well. ↩